In this post I come back to the basic reproduction number, a concept which seems to me like a thorn in my flesh. Some of what I write here might seem rather like a repetition of things I have written in previous posts but I feel a strong need to consolidate my knowledge on this issue so as to possibly finally extract the thorn. The immediate reason for doing so is that I have been reading the book ‘Infectious diseases of humans’ by Anderson and May. I find this book very good and pleasant to read but my progress was halted when I came to Section 2.2 on p. 17 whose title is ‘The basic reproductive rate of a parasite’. (The question of whether it is better to use the word ‘rate’ or the word ‘number’ in this context is not the one that interests me.) What is written there is ‘The basic reproductive rate, 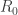 is essentially the average number of successful offspring a parasite is capable of producing’. It is clear that this is not a precise mathematical definition, as shown in particular by the use of the word ‘essentially’. In that section there is further discussion of the concept without a definition. As a mathematician I am made uneasy by a discussion using what is apparently a mathematical concept without giving a definition. A possible reaction to this unease would be to say, ‘Be patient, maybe a definition will be given later in the book’. Unfortunately I have not been able to find a definition elsewhere in the book. I also checked whether it might not be included in some supplementary material or appendices. Later in the book this quantity is calculated in some models. This might provide an opportunity for reverse engineering the definition. This book is not aimed at mathematicians, which is an excuse for the lack of a definition. Next I turned to the book ‘Virus dynamics’ by Nowak and May which is related but a bit more mathematical. Here the place I get stuck is on p. 19. Again there is a definition of in words, ‘the number of newly infected cells that arise from any one infected cell when almost all cells are uninfected’. Just before that a specific model, the ‘basic model of virus dynamics’ has been introduced.
is essentially the average number of successful offspring a parasite is capable of producing’. It is clear that this is not a precise mathematical definition, as shown in particular by the use of the word ‘essentially’. In that section there is further discussion of the concept without a definition. As a mathematician I am made uneasy by a discussion using what is apparently a mathematical concept without giving a definition. A possible reaction to this unease would be to say, ‘Be patient, maybe a definition will be given later in the book’. Unfortunately I have not been able to find a definition elsewhere in the book. I also checked whether it might not be included in some supplementary material or appendices. Later in the book this quantity is calculated in some models. This might provide an opportunity for reverse engineering the definition. This book is not aimed at mathematicians, which is an excuse for the lack of a definition. Next I turned to the book ‘Virus dynamics’ by Nowak and May which is related but a bit more mathematical. Here the place I get stuck is on p. 19. Again there is a definition of in words, ‘the number of newly infected cells that arise from any one infected cell when almost all cells are uninfected’. Just before that a specific model, the ‘basic model of virus dynamics’ has been introduced.
The basic model is clearly defined in the book. It is a system of ordinary differential equations depending on some parameters. Depending on the values of these parameters there is one positive steady state or none. These two cases can be characterized by a certain ratio of the parameters. If this ratio is greater than one there is a positive steady state. If it is less than or equal to one there is none. We can introduce the notation for this quantity and call it the basic reproduction number. This is a clear and permissible mathematical definition and it is an interesting statement about the model that such a quantity exists and can be written down explicitly in terms of the parameters of the system. This definition does, however, have two disadvantages. There are many models similar to this one in the literature. Thus the question comes up: if I have a specific model does there exist a quantity analogous to and if so how can I calculate it? The other is the idea that is not just a mathematical quantity. It potentially contains useful biological insights and that is something I would like to understand.
Is there more to be learned about this issue from the book of Nowak and May? They do have a kind of derivation in words of the expression for . It is obtained as the product of three quantities, each of which comes with a certain interpretation. Thus a strategy would be to try and understand these three quantities individually and then understand why it is relevant to consider their product. At this point I will introduce some insights which I mentioned in a previous post. For many models the existence of a positive steady state is coupled to the stability of a steady state on the boundary of the non-negative orthant (disease-free steady state). I believe that is really a quantity related to the disease-free steady state and that in a sense it is just a coincidence that it is related to the question of the existence of a positive steady state. This is illustrated by the fact that there are models exhibiting a so-called backward bifurcation where there do exist positive steady states in some cases with  . Beyond this, I believe that depends only on the linearization of the system about the disease-free steady state.
. Beyond this, I believe that depends only on the linearization of the system about the disease-free steady state.
As I have discussed elsewhere, the best source I know for understanding mathematically is a paper of van den Driessche and Watmough. There it is explained how, subject to making some choices, the linearization of the system at the disease-free steady state gives rise to something called the ‘next generation matrix’, let me abbreviate it by NGM. In that paper is defined to be the spectral radius of the NGM. Thus we obtain a rigorous definition of provided we have a rigorous definition of the NGM. In addition it is proved in that paper that the linearization at the disease-free steady state has an eigenvalue with positive real part precisely when  , a fact with obvious consequences for stability of that steady state. It is clearly stated in the paper that the NGM does not only depend on the system of ODE defining the model but also on the choices already mentioned. The first choice is that of the
, a fact with obvious consequences for stability of that steady state. It is clearly stated in the paper that the NGM does not only depend on the system of ODE defining the model but also on the choices already mentioned. The first choice is that of the  variables
variables  are supposed to correspond to infected individuals. A disease-free steady state is then by definition one at which these variables vanish. This means that if we have a specific model and a specific choice of boundary steady state where some unknowns vanish and we want to apply this approach the infected variables must be a subset of the unknowns which vanish there. It is not ruled out that they might be a proper subset. This discussion has made it clear to me what strategy I should pursue to make progress in this area. I should look in great detail at the part of the paper of van den Driessche and Watmough where the method is set up. Since I think this post is already long enough I will do that on another occasion.
are supposed to correspond to infected individuals. A disease-free steady state is then by definition one at which these variables vanish. This means that if we have a specific model and a specific choice of boundary steady state where some unknowns vanish and we want to apply this approach the infected variables must be a subset of the unknowns which vanish there. It is not ruled out that they might be a proper subset. This discussion has made it clear to me what strategy I should pursue to make progress in this area. I should look in great detail at the part of the paper of van den Driessche and Watmough where the method is set up. Since I think this post is already long enough I will do that on another occasion.























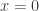 is always a steady state. Hence
is always a steady state. Hence  for a smooth function
for a smooth function 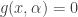 could potentially have a bifurcation at the origin but here I specifically consider the case where it does not. The assumptions are
could potentially have a bifurcation at the origin but here I specifically consider the case where it does not. The assumptions are  and
and  . Moreover it is assumed that
. Moreover it is assumed that  . By the implicit function theorem the zero set of
. By the implicit function theorem the zero set of  . If
. If  there exist positive steady states for
there exist positive steady states for 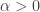 and if
and if  there exist positive steady states with
there exist positive steady states with 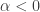 . The conditions which have been required of
. The conditions which have been required of  and
and  . Since
. Since  and the origin is a bifurcation point for
and the origin is a bifurcation point for  and
and  . It follows from the implicit function theorem, applied to
. It follows from the implicit function theorem, applied to  . Thus we see how many steady states there are for each value of
. Thus we see how many steady states there are for each value of  and
and  for the bifurcation are defined. They are expressed in invariant form both in terms of the extrinsic dynamical system and in a form intrinsic to the centre manifold. In the coordinate form used above
for the bifurcation are defined. They are expressed in invariant form both in terms of the extrinsic dynamical system and in a form intrinsic to the centre manifold. In the coordinate form used above  and
and  . Theorem 4 of the paper makes statements about the existence and stability of positive steady states which are essentially equivalent to those made above when it is taken into account that in the situation of the theorem the centre manifold is asymptotically stable with respect to perturbations in the transverse directions. It does not say more than that. The fact, often seen in pictures of backward bifurcation that the unstable branch undergoes a fold bifurcation is not included. In particular the fact that for some parameter values there exists more than one positive steady state is not included.
. Theorem 4 of the paper makes statements about the existence and stability of positive steady states which are essentially equivalent to those made above when it is taken into account that in the situation of the theorem the centre manifold is asymptotically stable with respect to perturbations in the transverse directions. It does not say more than that. The fact, often seen in pictures of backward bifurcation that the unstable branch undergoes a fold bifurcation is not included. In particular the fact that for some parameter values there exists more than one positive steady state is not included. in terms of derivatives of
in terms of derivatives of  . In fact we will only write out those terms explicitly which do not always vanish at the bifurcation point. The result is
. In fact we will only write out those terms explicitly which do not always vanish at the bifurcation point. The result is 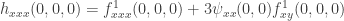 .
.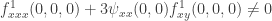 . Note, however, that the expression
. Note, however, that the expression  is not intrinsic to the centre manifold. Because of the vanishing of the first derivatives the second order derivatives
is not intrinsic to the centre manifold. Because of the vanishing of the first derivatives the second order derivatives  and
and  define tensors in the full dimension of the dynamical system. Hence we can write
define tensors in the full dimension of the dynamical system. Hence we can write  invariantly in the form
invariantly in the form 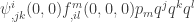 . It remains to compute
. It remains to compute  . The invariance of the centre manifold implies that
. The invariance of the centre manifold implies that  . Hence
. Hence 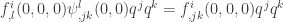 . This equation has a unique solution for
. This equation has a unique solution for 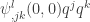 . In this way one of the conditions for a generic cusp bifurcation can be expressed in an invariant way. This corresponds to (8.128) in the book of Kuznetsov. In trying to understand these things better I was confused by equation (5.28) in the book which should be almost the same as (8.128) but in fact contains a typo. There is a repetition of
. In this way one of the conditions for a generic cusp bifurcation can be expressed in an invariant way. This corresponds to (8.128) in the book of Kuznetsov. In trying to understand these things better I was confused by equation (5.28) in the book which should be almost the same as (8.128) but in fact contains a typo. There is a repetition of  . For a generic cusp bifurcation we need two parameters
. For a generic cusp bifurcation we need two parameters 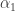 and
and 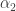 . The genericity condition involving derivatives with respect to parameters can easily translated into an invariant form. The result is
. The genericity condition involving derivatives with respect to parameters can easily translated into an invariant form. The result is Formulae similar to those just given were used in a paper I wrote with Juliette Hell some years ago (Nonlin. Analysis: RWA. 24, 175). Looking back at that I have the feeling that we must have been doing some sleepwalking when writing that paper. Or maybe I was sleepwalking and Juliette was paying attention. In any case, the final result was correct.
Formulae similar to those just given were used in a paper I wrote with Juliette Hell some years ago (Nonlin. Analysis: RWA. 24, 175). Looking back at that I have the feeling that we must have been doing some sleepwalking when writing that paper. Or maybe I was sleepwalking and Juliette was paying attention. In any case, the final result was correct. and a steady state
and a steady state 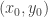 . The usual aim is to understand systems up to certain transformations. One type of transformation is of the form
. The usual aim is to understand systems up to certain transformations. One type of transformation is of the form  . A second is of the form
. A second is of the form 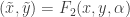 . A third is of the form
. A third is of the form  . With the assumptions which have been made we can do a translation to achieve
. With the assumptions which have been made we can do a translation to achieve 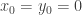 . Assume now that the linearization of the system at the origin is diagonalizable with rank one. Then it has one eigenvalue zero and one non-zero eigenvalue. It can be diagonalized by a linear transformation of the coordinates. After these transformations the system has almost been reduced to the form in the last post, except that there is a non-zero constant in front of the first summand in the evolution equation for
. Assume now that the linearization of the system at the origin is diagonalizable with rank one. Then it has one eigenvalue zero and one non-zero eigenvalue. It can be diagonalized by a linear transformation of the coordinates. After these transformations the system has almost been reduced to the form in the last post, except that there is a non-zero constant in front of the first summand in the evolution equation for  which might not be
which might not be  . It can be reduced to the latter case by rescaling the time coordinate. A similar process can be carried out when the centre manifold is of higher codimension. Then the variable
. It can be reduced to the latter case by rescaling the time coordinate. A similar process can be carried out when the centre manifold is of higher codimension. Then the variable 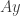 for an invertible matrix
for an invertible matrix  . The function
. The function  defining the centre manifold is then also vector-valued. The centre manifold analysis can be done in a manner very similar to what we have seen already.
defining the centre manifold is then also vector-valued. The centre manifold analysis can be done in a manner very similar to what we have seen already.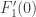 and so the fact of its being non-zero is unchanged. The third type of transformation just scales all the relevant quantities by the non-zero factor
and so the fact of its being non-zero is unchanged. The third type of transformation just scales all the relevant quantities by the non-zero factor 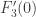 and so also does not change whether these are zero or not. It remains to consider the second type of transformation. At this point a more geometrical point of view will be adopted. We change the notation for the right hand side of the equations to
and so also does not change whether these are zero or not. It remains to consider the second type of transformation. At this point a more geometrical point of view will be adopted. We change the notation for the right hand side of the equations to  . These are the components of a parameter-dependent vector field which satisfies
. These are the components of a parameter-dependent vector field which satisfies 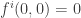 . Because of this condition the derivative
. Because of this condition the derivative 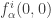 defines a vector at the origin independently of the transformation of the second type. The linearization
defines a vector at the origin independently of the transformation of the second type. The linearization  of the vector field at the origin defines a tensor. We suppose as before that it is diagonalizable and of rank one. Let
of the vector field at the origin defines a tensor. We suppose as before that it is diagonalizable and of rank one. Let 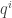 be a vector spanning the kernel of
be a vector spanning the kernel of  . Similarly there is a one-form
. Similarly there is a one-form  with
with 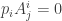 . It is unique up to rescaling and we choose it to satisfy
. It is unique up to rescaling and we choose it to satisfy  . With these notations the condition previously written in the form
. With these notations the condition previously written in the form 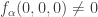 can be written in the invariant form
can be written in the invariant form  . The condition previously written in the form
. The condition previously written in the form 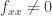 can be written in the invariant form
can be written in the invariant form  . Here we use the notation
. Here we use the notation  . It is because the vector field vanishes at the origin and
. It is because the vector field vanishes at the origin and 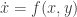 and
and 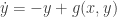 . This example is general enough to illustrate several important ideas. Here
. This example is general enough to illustrate several important ideas. Here 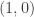 . It follows that there exists a centre manifold of the form
. It follows that there exists a centre manifold of the form 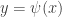 , where
, where  . Substituting this into the evolution equation for
. Substituting this into the evolution equation for  . This is a leading order approximation to the flow on the centre manifold. If
. This is a leading order approximation to the flow on the centre manifold. If 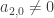 we can use it to read off the stability of the origin within the centre manifold. This argument uses no information about the way the centre manifold deviates from the centre subspace, i.e. how fast
we can use it to read off the stability of the origin within the centre manifold. This argument uses no information about the way the centre manifold deviates from the centre subspace, i.e. how fast 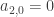 we need to go further.
we need to go further. . Call this equation (*). It can be analysed with the help of the Taylor expansions
. Call this equation (*). It can be analysed with the help of the Taylor expansions 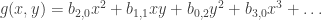 and
and  . Substituting these into (*) we see that the left hand side is of order three. Thus the same must be true of the right hand side and we get
. Substituting these into (*) we see that the left hand side is of order three. Thus the same must be true of the right hand side and we get 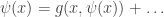 and
and 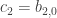 . Substituting this back into the evolution equation for
. Substituting this back into the evolution equation for  . Thus if
. Thus if 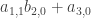 . If it is zero we can do another loop of the same kind. Looking at the third order terms in the equation (*) we get
. If it is zero we can do another loop of the same kind. Looking at the third order terms in the equation (*) we get 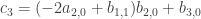 . This allows the fourth order term in the evolution equation for
. This allows the fourth order term in the evolution equation for 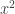 in the equation for
in the equation for  . If it is non-zero we are done. If it is zero use the equation (*) to determine the leading term in the expansion of the centre manifold. Put this information into the equation for
. If it is non-zero we are done. If it is zero use the equation (*) to determine the leading term in the expansion of the centre manifold. Put this information into the equation for  and
and 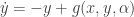 , where
, where 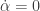 . The origin is a steady state of the extended system and the centre manifold at that point is of dimension two. It is of the form
. The origin is a steady state of the extended system and the centre manifold at that point is of dimension two. It is of the form  . Suppose that we are in the case
. Suppose that we are in the case  . Of course the equation
. Of course the equation  remains unchanged. We can now check the conditions for a generic fold bifurcation in the system reduced to the centre manifold. The first is
remains unchanged. We can now check the conditions for a generic fold bifurcation in the system reduced to the centre manifold. The first is  . The second is
. The second is 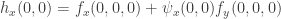 . Hence
. Hence 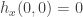 is equivalent to
is equivalent to  . The third involves
. The third involves  . We see that
. We see that  is equivalent to
is equivalent to  . The fourth involves
. The fourth involves 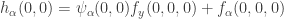 . We see that
. We see that  is equivalent to
is equivalent to  , where
, where  is the concentration of virus in the environment which may cause infection. What should we choose for the function
is the concentration of virus in the environment which may cause infection. What should we choose for the function  and the Hill function where
and the Hill function where  . The Michaelis-Menten function has a mechanistic basis, introduced by the people who it is now named after. Hill also presented a mechanistic basis for his function. It incorporates the phenomenon of cooperative binding, with the original example being the binding of oxygen to haemoglobin. Another example of the choice of response functions occurs in predator-prey models in ecology. Here
. The Michaelis-Menten function has a mechanistic basis, introduced by the people who it is now named after. Hill also presented a mechanistic basis for his function. It incorporates the phenomenon of cooperative binding, with the original example being the binding of oxygen to haemoglobin. Another example of the choice of response functions occurs in predator-prey models in ecology. Here  ) and Holling type III (
) and Holling type III ( ). We found that the case
). We found that the case  gives rise to backward bifurcations while the case
gives rise to backward bifurcations while the case  ,
,  . The first
. The first 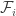 ,
,  and
and  where
where  are all non-negative. This is condition (A1) of the paper. On the right hand side of this type of system there are positive and negative terms. If we take
are all non-negative. This is condition (A1) of the paper. On the right hand side of this type of system there are positive and negative terms. If we take  is also used. As is usual in reaction networks
is also used. As is usual in reaction networks  when
when  . This is condition (A2) of the paper. The
. This is condition (A2) of the paper. The  . This is condition (A3) of the paper. It restricts the ambiguity in the splitting. In condition (A4) the set of disease-free steady states is supposed to be invariant and this leads to the vanishing of some non-negative terms at those points. In general this condition restricts the choice of the infected compartments. In the fundamental model of virus dynamics the infected variables are a subset of
. This is condition (A3) of the paper. It restricts the ambiguity in the splitting. In condition (A4) the set of disease-free steady states is supposed to be invariant and this leads to the vanishing of some non-negative terms at those points. In general this condition restricts the choice of the infected compartments. In the fundamental model of virus dynamics the infected variables are a subset of 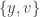 . However choosing it to be a proper subset would violate condition (A4). Thus for this model there is no choice at this point. There does remain a choice in splitting the positive terms, as already discussed in a
. However choosing it to be a proper subset would violate condition (A4). Thus for this model there is no choice at this point. There does remain a choice in splitting the positive terms, as already discussed in a 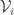 also splits the linearization into a sum. It is an elementary consequence of the assumptions made that some of the entries of the matrices occurring in these decompositions are zero. It can also be shown that some entries are non-negative. To describe a new infection we can take an initial datum close to the disease-free steady state. Then we may reasonably suppose (leaving aside questions of proof) that the actual dynamics is well-approximated by the linearized dynamics during an initial period. Under the given assumptions the linearization is block lower triangular. The linearized evolution is partially decoupled and the uninfected variables decay exponentially. So the dynamics essentially reduces to that of the infected variables and is generated by the upper left block, called
also splits the linearization into a sum. It is an elementary consequence of the assumptions made that some of the entries of the matrices occurring in these decompositions are zero. It can also be shown that some entries are non-negative. To describe a new infection we can take an initial datum close to the disease-free steady state. Then we may reasonably suppose (leaving aside questions of proof) that the actual dynamics is well-approximated by the linearized dynamics during an initial period. Under the given assumptions the linearization is block lower triangular. The linearized evolution is partially decoupled and the uninfected variables decay exponentially. So the dynamics essentially reduces to that of the infected variables and is generated by the upper left block, called  in the paper. We get an exponential phase of decay with populations proportional to
in the paper. We get an exponential phase of decay with populations proportional to 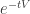 . During this phase the number of susceptibles is approximately constant, equal to its value at the disease-free steady state. Hence we get an explicit expression for the rate of infection in this phase. Integrating this with respect to time gives an expression for the ratio of total number of individuals infected in that phase as a function of the original number of individuals in the different compartments. It is given by the matrix
. During this phase the number of susceptibles is approximately constant, equal to its value at the disease-free steady state. Hence we get an explicit expression for the rate of infection in this phase. Integrating this with respect to time gives an expression for the ratio of total number of individuals infected in that phase as a function of the original number of individuals in the different compartments. It is given by the matrix  , which is the NGM previously mentioned.
, which is the NGM previously mentioned. . We look for a solution with
. We look for a solution with 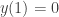 and
and  . The first two terms look like the expression for the Laplacian of a spherically symmetric function in
. The first two terms look like the expression for the Laplacian of a spherically symmetric function in  which are vaguely related to fluid flow around a cylinder and flow around a sphere, respectively. It turns out that the case
which are vaguely related to fluid flow around a cylinder and flow around a sphere, respectively. It turns out that the case  . We would like to understand what happens to this solution as
. We would like to understand what happens to this solution as  . It is possible to find an asymptotic expansion in
. It is possible to find an asymptotic expansion in  but it is not enough to use powers of
but it is not enough to use powers of  . This is a singular limit although the parameter in the equation only occurs in a lower order term. This happens because the equation is defined on a non-compact region.
. This is a singular limit although the parameter in the equation only occurs in a lower order term. This happens because the equation is defined on a non-compact region.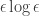 . This extra term is the switchback term. Up to this point all this is formal. One method of obtaining rigorous proofs for the asymptotics is to use GSPT, as done in two papers of Popovic and Szmolyan (J. Diff. Eq. 199, 290 and Nonlin. Anal. 59, 531). There is an introduction to this work in the book but I felt the need to go deeper and I looked at the original papers as well. To fit the notation of those papers I replace
. This extra term is the switchback term. Up to this point all this is formal. One method of obtaining rigorous proofs for the asymptotics is to use GSPT, as done in two papers of Popovic and Szmolyan (J. Diff. Eq. 199, 290 and Nonlin. Anal. 59, 531). There is an introduction to this work in the book but I felt the need to go deeper and I looked at the original papers as well. To fit the notation of those papers I replace  . Reducing the equation to first order by introducing
. Reducing the equation to first order by introducing 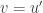 as a new variable leads to a non-autonomous system of two equations. Introducing
as a new variable leads to a non-autonomous system of two equations. Introducing  as a new dependent variable and using it to eliminate
as a new dependent variable and using it to eliminate  from the right hand side of the equations in favour of
from the right hand side of the equations in favour of  leads to an autonomous system of three equations. This allows the original problem to be reformulated in the following geometric way. The
leads to an autonomous system of three equations. This allows the original problem to be reformulated in the following geometric way. The  is denoted by
is denoted by  . The aim is to find a solution which starts at a point of the form
. The aim is to find a solution which starts at a point of the form 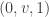 and tends to
and tends to  . A solution of this form for
. A solution of this form for  . For
. For 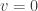 . In the case
. In the case  and depend smoothly on
and depend smoothly on  . Suppose that for some value
. Suppose that for some value 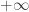 for
for  and for another value
and for another value  the solution tends to
the solution tends to  . Then we might expect that in between there is a value
. Then we might expect that in between there is a value 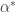 for which the solution is bounded. We could try to home in on the value of
for which the solution is bounded. We could try to home in on the value of  . Let
. Let  where
where 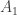 and
and 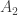 are non-empty and open and
are non-empty and open and  then
then  has a periodic solution. In fact this is related to the Brouwer fixed point theorem specialised to dimension one (which of course is elementary to prove). The next example is to show that
has a periodic solution. In fact this is related to the Brouwer fixed point theorem specialised to dimension one (which of course is elementary to prove). The next example is to show that  has a periodic solution. After that this is generalised to the case where
has a periodic solution. After that this is generalised to the case where 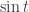 is replaced by an arbitrary bounded continuous function on
is replaced by an arbitrary bounded continuous function on 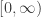 and we look for a bounded solution. The next example is a kind of forced pendulum equation
and we look for a bounded solution. The next example is a kind of forced pendulum equation  and the aim is to find a solution which is at the origin at two given times. In the second chapter a wide variety of examples is presented, including those just mentioned, and used to illustrate a number of general points. The key point in a given application is to find a good choice for the subsets. There is also a discussion of two-parameter shooting and its relation to the topology of the plane. This has a very different flavour from the arguments I am familiar with. It is related to Wazewski’s theorem (which I never looked at before) and the Conley index. The latter is a subject which has crossed my path a few times in various guises but where I never really developed a warm relationship. I did spend some time looking at Conley’s book. I found it nicely written but so intense as to require more commitment than I was prepared to make at that time. Perhaps the book of Hastings and McLeod can provide me with an easier way to move in that direction.
and the aim is to find a solution which is at the origin at two given times. In the second chapter a wide variety of examples is presented, including those just mentioned, and used to illustrate a number of general points. The key point in a given application is to find a good choice for the subsets. There is also a discussion of two-parameter shooting and its relation to the topology of the plane. This has a very different flavour from the arguments I am familiar with. It is related to Wazewski’s theorem (which I never looked at before) and the Conley index. The latter is a subject which has crossed my path a few times in various guises but where I never really developed a warm relationship. I did spend some time looking at Conley’s book. I found it nicely written but so intense as to require more commitment than I was prepared to make at that time. Perhaps the book of Hastings and McLeod can provide me with an easier way to move in that direction.